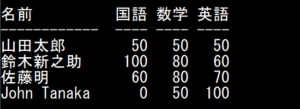
全角がある場合は表示がずれる
format()メソッドで桁を指定した場合、全角があると表示がずれてしまいます。
|
1 2 3 4 5 6 |
data = [["山田太郎",50,50,50],["鈴木新之助",100,80,60],["佐藤明",60,80,70],["John Tanaka",0,50,100]] print("名前 国語 数学 英語") print("------------ ---- ---- ----") for chara in data: print("{:14s} {:3d} {:3d} {:3d}".format(chara[0], chara[1], chara[2], chara[3])) |
◆実行例
全角は表示するスペースは2文字分ですが、format()メソッドでは全角でも1文字として計算してしまいます。
このような場合は、表示する文字が全角かどうかを判定して全角は2文字として計算します。
文字が全角かどうかを調べるのには、unicodedata.east_asian_width()関数を使います。
east asian width は東アジアの文字幅です。
なお、unicodedata.east_asian_width()関数を使うには、unicodedataをインポートする必要があります。
戻り値 = unicodedata.east_asian_width(文字)
戻り値の内容は、以下のようになります。
| 戻り値 | 全角/半角 | 内容 |
| F | 全角 | 全角英数 |
| H | 半角 | 半角カナ |
| W | 全角 | 漢字、ひらがな、カタカナ |
| Na | 半角 | 半角英数 |
| A | 全角 | ギリシア文字など |
| N | 全角でも半角でもない | アラビア文字など |
戻り値が「F」「W」「A」が全角となります。
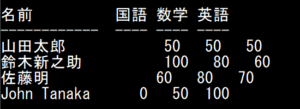
全角があっても表示がずれないようにする
上記をふまえて、スクリプトを以下のように書き直します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import unicodedata data = [["山田太郎",50,50,50],["鈴木新之助",100,80,60],["佐藤明",60,80,70],["John Tanaka",0,50,100]] print("名前 国語 数学 英語") print("------------ ---- ---- ----") for chara in data: count = 0 for c in chara[0]: if unicodedata.east_asian_width(c) in "FWA": count += 1 col = 14 - count print("{:{width}s} {:3d} {:3d} {:3d}".format(chara[0], chara[1], chara[2], chara[3], width=col)) |
◆実行例